





Most people head to their favourite search engines such as Google or Bing when they need to find something online. If you type “search engine” into Google, you’ll get 1.43 billion results in just 0.69 seconds.
Web users can use a search engine, a service provided by a third party, to locate specific information across the internet’s vast resources (known as World Wide Web). Users who type something into a search engine are presented with a list of results that may include websites, photos, videos, or other online data relevant to their query based on their semantic similarity.
In addition, a search engine is a piece of software that allows users to perform keyword searches to locate certain documents on the web. Even though there are millions of websites, search engines can give quick results because they constantly scan the Internet and index any pages they find.
Search engines use algorithms, a set of steps in a process to look at the titles, contents, and keywords of the pages they have indexed to determine which ones are most relevant to a user’s search.
Search engine optimisation (SEO) is a technique businesses use to have their websites ranked higher by search engines in response to certain keyword queries.
This article will provide an overview of search engines, give some examples of their use, and explain their work stages. You should read it all the way through.
What is a Search Engine?

A search engine is a type of computer programme that is (often web-based) used to collect and organise content from all over the internet. It is also a web search engine and an online search engine.
The user initiates a query composed of various keywords or phrases, and the search engine answers by delivering a list of results that are most relevant to the user’s inquiry. The results may be presented as links to web pages, images, videos, or other online data types.
People have access to a wide variety of search engines. Nonetheless, a small number of companies control the majority of the industry. Users can search for material on the internet using various keywords thanks to search engines.
When the user enters a query into a search engine, a search engine results page (SERP) returns, ranking the pages found based on their relevance. The method that each search engine uses to determine rankings is unique.
Frequent updates are made to the algorithms used by search engines and the programmes that determine the order in which results are shown. They intend to learn how users search so that they can provide the most relevant results to the questions asked by users. This means giving the most weight to the best and most useful pages.
Many people believe that internet browsers and search engines are the same things. This misconception partly originated because the Google Chrome browser integrated search engine functions into the web address bar. However, search engines are web services that are developed with the sole purpose of retrieving information. Even though a browser makes it easy to get to both of them, they are different technologies.
What is the aim of Search Engines Algorithm?
The main goal of search engines is to help people find information on the internet quickly and efficiently. When you type a query into a search engine, like Google, it uses a special computer programme called a search algorithm to figure out which are the most important pages for your search terms.
Here’s how search engine works in algorithms
Crawling and Indexing
- Other search engines work using their own web crawlers to go through the vast majority of web content. These crawlers on Google discovers new pages and update information about known pages.
- The information collected during this crawling process is then organised and stored in a huge database called indexing. Crawling and indexing are like a giant catalog of all the pages on the internet.
Search Algorithm
- When you type in a search query, the search engine uses a complex formula, called a search algorithm, to find the most relevant pages from Google’s index through an indexing process.
- The search algorithms take into account various factors, such as the page’s content, meta tags, structured data, and high-quality backlinks from external websites.
Relevance to the user’s query
- Search engines aim to provide the most helpful content in response to a user’s particular query. They try to match the search terms with the content on important pages. This is important in digital marketing to reach the target market.
Location and Page Quality:
- The search works also consider the user’s location and the quality of the pages. How many pages with relevant and high-quality content are more likely to show up in search results? Most likely, a lot.
User-Friendly Results
- The goal is to deliver relevant results in digital marketing. Search engines understand the importance of page speed and make sure users can access information as fast as possible by answering the user query.
Discovering New Pages
- Search engines work by constantly looking for new pages and updating them, like the Google index. This is crucial to ensuring that users can find the latest and most relevant information.
Helping Site Owners
- Search engines offer tools like Google Search Console to help site owners understand how their pages are performing in search results. This information allows site owners to optimize their content for better search engine rankings
Machine Learning
- Search engines use machine learning to improve their algorithms over time. This helps them better understand user behaviour and deliver more accurate and personalised results.
Examples of Search Engines

Though no search engine is without flaws, some are certainly more widely used than others. We’ve compiled a list of five popular search engines that people use frequently.
Internet Archive
The Internet Archive is an online library where users can access digital resources for free. This is a San Francisco-based digital library with a focus on preserving knowledge for the public good. It is useful for tracking the development of specific fields over time. You can find websites, software, games, movies, music, moving pictures, and a large library of public domain books.
The Internet Archive not only works to make the web open and easy to use but also to protect and keep net neutrality.
Yahoo!
If you want to have a reliable search engine, Yahoo! Search is another excellent option. Yet, for a good chunk of its existence, it has provided the user interface while relying on third parties to handle the searchable index and web crawling.
Before Google took it over in 2004, Inktomi was responsible for it. Before Yahoo! Search made a deal with Microsoft in 2009 to work together, it ran on its own and used index and crawlers.
Google was established 25 years ago and is getting bigger and better. In today’s era, Google is one of the most popular search engines. It processes more than 5 billion searches each day and accounts for more than 90% of the market share (August 2019).
It has become so popular that “I googled it/that” is often used to mean someone looked something up on the internet.
Bing
Bing is the successor to Microsoft’s previous search engines, which include MSN Search, Windows Live Search, and Live Search. Although Bing has gained many supporters since its 2009 debut, its original goal of surpassing Google has not been realised.
Nonetheless, Bing trails only Google and Baidu regarding market share among search engines worldwide. Forty different languages have editions of it.
Ask.com
Ask.com, formerly known as Ask Jeeves, is a bit different from Google and Bing in that it presents search results in the form of questions and answers. Although Ask.com spent a good deal of time trying to catch up to the major search engines, it now relies on its extensive archive and user contributions, in addition to the services of an undisclosed and outsourced third-party search provider, to supply its answers.
How do Search Engines work?

To complete its tasks, a search engine will go through a series of processes, which will be explained thoroughly and separately. First, a web crawler will go through the process of searching the web for material that will then be added to the search engine’s index. These tiny bots can search an entire website, including its parts, subpages, and material such as videos and photographs.
When a hyperlink points to an external website, it must be evaluated to determine if it leads to an inside page or a new source to crawl. Larger websites typically provide the search engine with a unique XML sitemap that functions as a roadmap for the site itself. This is done to help the bots crawl more efficiently.
When the bots have retrieved all the data, the crawler will add it to a vast online library containing all the URLs discovered. Then, when a user types something into a search engine, the algorithm in the search engine figures out which results are relevant and sends those results back to the user. A website needs to undergo this ongoing and iterative process, known as indexing, to be featured in the SERP.
The higher on the search engine results page (SERP) a website appears, the more relevant it should be to the queries by the user. Because most people only look at the top results, a website needs to have a high ranking for specific searches to ensure that it will be successful in terms of the amount of traffic it receives.
A whole science has emerged in recent years to ensure that a website, or at least some of its pages, “scales” the ranking to obtain the top ranks. The term “search engine optimisation” applies to this.
The results returned by early search engines were based primarily on the content of the pages that were being searched. However, as websites learned how to “game the system” by employing advanced SEO practices, algorithms became significantly more complicated. The returned search results can now be based on hundreds of different variables.
Each search engine currently employs its own unique algorithm to arrange the results of a search in a certain order. This algorithm considers many complicated factors, such as relevance, accessibility, usability, page speed, content quality, and the user’s goal.
Those SEOs frequently expend significant energy trying to decipher the algorithms because the companies are not transparent with how they operate. This is because their business is private, and they also don’t want search engine results to be manipulated.
The majority of search engines operate through the following three stages:
Crawling: How Search Engine Crawl your Site?
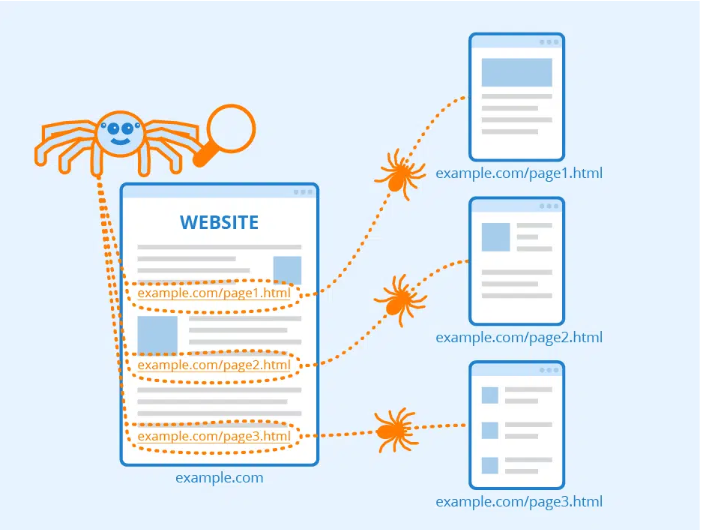
The process of locating material that is freely accessible to the public on the internet is referred to as “crawling,” and search engines accomplish it through the use of specialised software known as “web crawlers.” Web crawlers are sometimes called search engine crawling or spiders for their ability to index websites.
The search engine crawling procedure is complex, but crawlers and spiders locate the web servers that host websites and then explore those servers. The process is sophisticated, but the result is the same.
For each website, its own web crawlers determine the number of pages it has and the format of its content (text, images, audio, video).
The crawlers will also follow any links on the website, whether internal links that connect to other pages while on the same site or external links that lead to other websites. They will use these links to find more pages on the discovered URLs.
Information gathered during crawling is organized into an index, which serves as a catalog of all the discovered web pages. It’s now time for the site to proceed to the next stage of the process – indexing.
Why a Page May Not Show in Search Results?
No Crawling Access
- If a web crawler cannot access a website due to crawl errors, technical issues, or restrictions, the pages won’t be indexed.
Low-Quality Content
- Pages with low-quality or duplicated content may be skipped, as search engines aim to provide valuable results to users.
No External Links
- Pages with no external links pointing to them may be less likely to be discovered, as crawlers often use these links to navigate.
Use of “Noindex” Tag:
- Website owners can use a “noindex” tag to instruct crawlers not to index certain pages. This is like putting a “Do Not Disturb” sign on a door.
Ensuring Faster Crawling
- Websites use a file called “robots.txt” to guide crawlers on which areas to explore and which to avoid. It’s like providing a map with specific instructions.
XML Sitemap
- An XML sitemap is like a roadmap that explicitly lists all the pages on a site, making it easier for crawlers to navigate and index.
Search Engine Submission
- Website owners can submit their sites to other search engines like Google and Bing, signalling the presence of their website for crawling.
Indexing: How does it Works?
The information found by the crawlers is then arranged, categorised, and saved so that it may be processed by the algorithms later and presented to the search engine user. This process is referred to as indexing. The search engine doesn’t keep all of the page’s content. Instead, the search algorithms only need the important information to determine if the page is relevant for search engine rankings purposes.
The search engine will try to understand and organise the content on a web page using ‘keywords.’ If you follow the best SEO practices, the search engine index will have an easier time understanding your material, which will help you rank higher for the appropriate search queries.
Checking Indexed Pages in Google
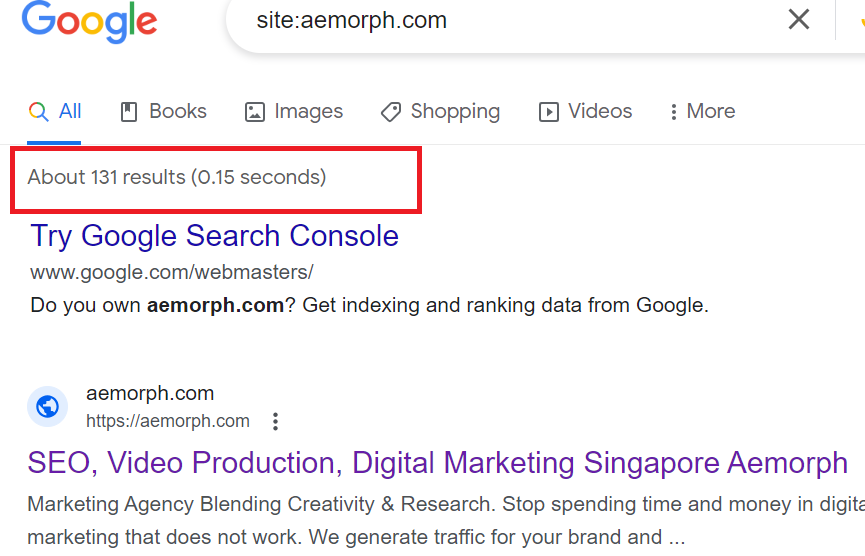
Using Google Search
- Go to the Google search bar.
- Type site:yourdomain.com and press Enter. Google will display a list of all indexed pages from your specified domain.
Checking Indexed Pages in Google Search Console
Create a free Google Search Console account and add your website.
Then look at the Indexed Pages report located under Pages > Indexing.
How to Index a Page?
- XML SitemapCreating an XML sitemap that lists all the discovered URLs on your website helps search engines understand your site’s structure and helps faster indexing.
- Robots.txtUsing a robots.txt file allows you to guide search engine crawlers on which parts of your site to index and which to exclude.
- Fetch as GoogleGoogle Search Console provides a “Fetch as Google” tool that allows you to submit specific URLs for indexing. This signals to Google that you want those pages to be considered for inclusion in the search index.
Ranking: How do Search Engine Rank Pages?
An index is searched for appropriate information when a search query is entered into a search engine. The findings are then arranged hierarchically by an algorithm. On search engine results pages, ranking is placing items in a specific order (SERPS).
The goal of search engine algorithms has always been to give more accurate and relevant answers to queries from search engine users. The algorithms that are utilised by various search engines produce results that are distinct from one another. This has caused these algorithms to get more complicated over time.
What are Search Algorithms?
A search algorithm refers to the complex set of rules and calculations used by search engines to determine the ranking of web pages in their search results. Search engines like Google employ sophisticated algorithms to analyze various factors on a webpage and determine its relevance and quality in relation to a user’s search query.
Google Ranking Factors
- Backlinks
Search engines consider the number and quality of backlinks pointing to a page. Backlinks act like votes of confidence from other websites, indicating the page’s credibility and authority. Google values links from trustworthy sources.
- RelevanceThe content on a page should match the user’s search intent. Search engines analyse the relevance of the page’s content to the search query, emphasising keywords, headings, and overall context. Google assesses the use of keywords, user engagement, and overall content quality.
- FreshnessThe content matters. Fresh and up-to-date information is often given higher priority. This is especially relevant for topics that evolve, like news or technology updates. Google values recent and updated content, especially for searches with a temporal aspect.
- Page SpeedThe speed at which a page loads is crucial. Slow-loading pages can result in a poor user experience, so search engines prioritise faster-loading pages in their rankings. Google considers page speed as a ranking factor.
- Mobile-FriendlinessWith the increasing use of mobile devices, search engines favor pages that are mobile-friendly. Responsive design and usability on various screen sizes contribute to a better user experience.
How do Search Engines personalize search results?
Search engines personalize search results by employing various techniques to tailor the information presented to individual users based on their preferences, behavior, and context.
User History
Search engines consider a user’s search history to understand their interests and preferences. Previous searches, clicked links, and engagement with specific types of content help shape personalized results.
Location-based Personalization
Search engines may use the user’s location to provide localized and relevant results, such as nearby businesses, events, or services.
Personalized Preferences
Users can customize their search experience by setting preferences, such as language, region, and content type, influencing the relevance of search results.
Contextual Understanding
Search engines aim to understand the context of a user’s query, considering factors like intent, recent activities, and trending topics to provide more contextually relevant results.
Semantic Search
Search engines use semantic analysis to understand the meaning behind words, considering synonyms, related concepts, and natural language processing to improve result accuracy.
Conclusion
The intricate process of how search engines work involves crawling, indexing, and ranking, driven by complex algorithms and ranking factors. Search engines, such as Google, Bing, and others, play a pivotal role in helping users find information across the vast expanse of the internet.
Users initiate queries, and search engines respond by presenting a list of relevant results, including web pages, images, videos, and more.
Understanding the process of crawling and indexing reveals how search engines systematically explore the web, organize information, and create massive databases for efficient retrieval.
The use of web crawlers, XML sitemaps, and robots.txt files influences the speed and effectiveness of this process. Furthermore, the application of search engine optimization (SEO) techniques empowers businesses to enhance their online visibility and ranking.
The ranking phase, guided by intricate algorithms and factors such as backlinks, relevance, freshness, page speed, and mobile friendliness, determines the order of search results. Google, as a big search engine, relies on these factors to provide accurate and user-friendly outcomes.
Recognizing the importance of these factors allows website owners to optimize their content for improved visibility in search engine results pages (SERPs).
Ultimately, a comprehensive understanding of how search engines work empowers both users and website owners to navigate the digital landscape effectively.
As search engine algorithms continue to evolve, staying informed about best practices, algorithm updates, and SEO strategies becomes essential for achieving optimal online presence and success.




