




Robots.txt files control the behaviour of web crawlers and other automated bots visiting your entire site.
It is essential because it helps improve your website’s search engine optimization (SEO) by ensuring that the right pages are indexed.
Let’s discuss its definition, how they work, and how you can use them to improve your website’s SEO.
What is Robots.txt?
Robots.txt is a text file whose main purpose is to tell web spiders which pages on your entire website to crawl and which to ignore.
These are certain files with the primary purpose of preventing web crawlers from overloading your site with requests, but it also excludes other pages from being crawled altogether.
You can create a Robots.txt file using any text editor, but you must save it with a .TXT extension. Once you’ve made your Robots.txt file, you’ll need to upload it to the root directory of your website.
When a web robot visits your entire site, it will check for the presence of a Robots.txt and use the information inside to determine crawl pages and which to ignore.
If you don’t have a Robots.txt file, the crawler will assume it can crawl all the essential pages on your site.
Why Is Robots.txt Important?
Robots.txt is a necessary file for any website that wants to optimize its SEO. If you don’t already have a robots.txt file on your site, we highly recommend you create one.
Here’s a quick rundown on why robots.txt is so essential for your website’s SEO:
It helps to improve your website’s crawlability.
When you have a well-optimized robots.txt, it helps web robots index your pages more efficiently. It can help improve your website’s overall crawlability, which is a factor that other search engines take into account when ranking sites.
It can help you to avoid duplicate content issues.
If there are multiple versions of the same web page on your website (e.g. www and non-www versions), Google may index both versions as other pages. It can create the same content issues, negatively impacting your SEO.
It can help you to control how your website’s content is presented in search results.
By specifying the preferred version of your website’s pages in robots.txt, you can help ensure that these specific pages are the ones displayed in search results. It can help control how your website’s content is presented to potential visitors.
It can help you to manage server load.
If your website gets a lot of traffic from web crawlers, it can strain your web server resources. By specifying which pages to crawl in robots.txt, you can help to reduce the load on your web server and improve website performance.
It can give you more control over what is indexed.
You can specify in robots.txt the certain pages you don’t want to be indexed.- preventing search engines from indexing and displaying sensitive information in SERPs.
Components of Robots.txt file
A well-optimized Robots.txt file can help improve your site’s visibility in Google search results and prevent your pages from being inadvertently penalized by the algorithms.
There are five main components to a Robots.txt file:
1) User-agent
2) Disallow
3) Allow
4) Sitemap
5) Crawl-delay
User Agent
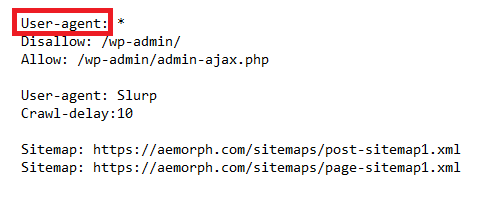
The user-agent field in robots.txt specifies which web robots are allowed to access a website.
User agents prevent malicious web robots from accessing sensitive information on a website or restrict access to certain areas of the site.
You must specify the user-agent field for each web robot to be allowed access.
Disallow

Adding “disallow” directives to a robots.txt tells crawlers which parts of your website they are not allowed to access.
Bots disallow pages on your site that you don’t want to show up in SERPs or if you want to prevent web robots from indexing your entire site.
One important thing to remember is that robots.txt directives are only suggestions – they are not enforceable, and crawlers can choose to ignore them if they want.
So while disallowing pages in your robots.txt files may prevent them from appearing in SERPs, it’s not a guarantee.
Allow
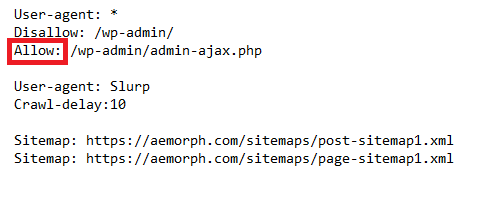
The “allow” directive in a robots.txt specifies which parts of a website are open to web robots and which are off limits. A site owner can permit specific types of traffic by including an allow directive.
Allow directives used in conjunction with disallow directives give fine-grained control over which parts of a website are accessible to crawlers.
For example, if a website only wants to allow search engine bots to index its content, it would include an allow directive specifying that. Conversely, if a site wants to block all crawlers, it would consist of a disallow directive for all traffic.
When a web robot visits a website, it checks the robots.txt files to see if there are any restrictions on what it can crawl. If there is an allow directive for the crawler’s user agent, then the crawler is free to access that part of the website.
If there is no allow directive, or if the directive is for a different user agent, then the crawler is not allowed to access that part of the website.
The allow directive is a relatively new addition to robots.txt files and is not universally supported. However, it is gaining popularity and is supported by all major search engines.
Sitemap
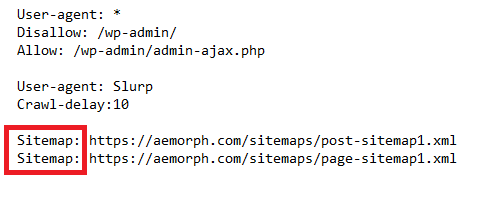
The sitemap is an XML file that lists all of the pages on your website.
You can add the sitemap to your robots.txt file so that the spiders can find it and crawl your website more efficiently. It is imperative to use a sitemap so that the spiders can find all of your pages if you have a large website.
The XML sitemap is a significant way to let the spiders know which pages on your site are most important. They can use this information to crawl sites more effectively and index pages more accurately.
You can add the sitemap to your robots.txt file in two ways. You can include it in line with the rest of your robots.txt file, or you can add it as another file. If you add it as a separate file, specify the file’s location in your robots.txt file so that the spiders can find it.
Crawl-delay
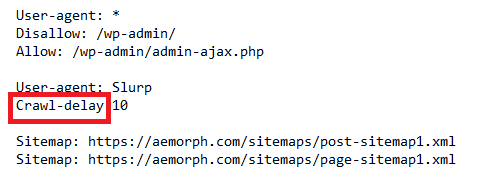
A crawl delay is a directive in a robots.txt file that tells crawlers how long to wait between requests to the same website. It can be helpful if you want to throttle the traffic going to your website or if your server cannot handle too many requests at once—the crawl delay is in seconds.
In general, a crawl delay should be used sparingly and only if necessary. It can throttle the amount of traffic if your website gets too much traffic from crawlers.
It will help reduce the load on your server and improve performance for your human visitors.
You should also make sure that your robots.txt file is well-organized and easy to understand so that crawlers can easily find and follow the directives.
How does robots.txt work?
Robots.txt tells web robots (also known as crawlers or spiders) which pages to crawl and to ignore. It is part of the standard for robot exclusion, also known as the Robots Exclusion Protocol.
The robots.txt file is in the main directory of your website. For a robot to crawl your site, it needs to be able to find the robots.txt file. The robot will then read the file and follow the instructions you’ve given it.
The robots.txt file is not required, but it is a good idea to have one. It is a simple way to tell search engine bots what you do and don’t want them to crawl on your site.
How Can You Find Your Robots.txt File on Your Website?
There are generally two ways you can find the robots.txt file for a given website.
The first one is finding robots.txt in the front-end. Simply navigate to your domain, and just add “/robots.txt”.
For example: https://aemorph.com/robots.txt
The second one is finding robots.txt in the backend. You may find it one of your plugins like Yoast SEO, Rankmath, SEO press, etc.
Once you’ve found the robots.txt file, open it in a text editor, and you’ll be able to see the set rules for crawlers.
If you can’t find a robots.txt file, or if the other file is empty, then this likely means that the site doesn’t have any specific rules in place for crawlers.
In this case, you should assume that the site is open to being crawled and indexed by Google.
SEO Best Practices
There are best practices when creating and managing your robot.txt file.
By following a best practice, you can ensure that visitors can find the information they need and that Google properly indexes your site.
Make It Simple to Find Your Robots.txt File
Search engine crawlers need to find the file to know which parts of your website to crawl and index.
If the file is well hidden or difficult to understand, the crawlers may miss it altogether and index less of your content as a result.
If you want to make your robot.txt file easier to find, there are a few things you can do.
For starters, you can include links to it in your website’s sitemap. You can also add links to it in the header or footer of your website.
Finally, you can submit your robot.txt file to search engines like Google and Bing.
Verify For Mistakes And Errors
Errors in the robots.txt can result in your website not being indexed by Google or, worse, blacklisted. It’s essential to check your robots.txt file for mistakes and errors regularly.
One way to check for errors in your robots.txt is to use the Google Webmaster Tools. Google Webmaster Tools will scan your robots.txt file and report any errors it finds.
Another way to check for errors in your robots.txt file is to use a tool like the Robots.txt Validator. This tool will scan your robots.txt and report any errors.
Robots.txt vs Meta Directives
Robots.txt contains instructions for search engine crawlers. It is a file you can create and upload to your website’s root directory, telling them which of your website’s pages they should and shouldn’t crawl.
Meta directives, on the other hand, are HTML tags that you can insert into the code of individual pages on your website. These tags also tell search engine crawlers which pages to crawl and which to ignore.
Robots.txt gives bots suggestions and meta directives provide very firm instructions on crawling and indexing a page’s content. Also, robots.txt dictates site or directory-wide crawl behaviour, while meta and x-robots can dictate indexation behaviour at the individual page level.




