




Tệp robots.txt kiểm soát cách các trình thu thập dữ liệu và các bot tự động khác truy cập và hoạt động trên website của bạn. Tệp này đóng vai trò quan trọng trong SEO vì giúp đảm bảo những trang phù hợp được lập chỉ mục. Bài viết sẽ giúp bạn hiểu robots.txt là gì, cách tệp này hoạt động và cách sử dụng robots.txt để cải thiện hiệu quả SEO cho website.
Robots.txt Là Gì?
Robots.txt là một tệp văn bản có mục đích chính là cho crawler (bot) của công cụ tìm kiếm biết những trang nào trên website được phép crawl (thu thập dữ liệu) và những trang nào cần bỏ qua. Tệp này được tạo ra nhằm hạn chế việc crawler gửi quá nhiều yêu cầu gây quá tải cho website, đồng thời loại trừ một số trang không cần thiết khỏi quá trình crawl. Bạn có thể tạo tệp robots.txt bằng bất kỳ trình soạn thảo văn bản nào, nhưng cần lưu với phần mở rộng .txt và tải tệp này lên thư mục gốc của website. Khi crawler truy cập website, nó sẽ kiểm tra sự tồn tại của robots.txt và dựa vào thông tin trong đó để quyết định trang nào được crawl và trang nào bị bỏ qua. Trong trường hợp website không có tệp robots.txt, crawler thường sẽ mặc định rằng nó có thể crawl tất cả các trang quan trọng trên website.
Tại Sao Robots.txt Lại Quan Trọng?
Robots.txt là một tệp cần thiết đối với các website hướng đến tối ưu SEO. Nếu website của bạn hiện chưa có tệp robots.txt, việc tạo tệp này nên được thực hiện sớm để hỗ trợ quá trình tối ưu kỹ thuật. Dưới đây là những lý do chính cho thấy vì sao robots.txt đóng vai trò quan trọng đối với SEO của website.
Cải thiện khả năng crawl của website
Khi robots.txt được thiết lập và tối ưu hợp lý, tệp này sẽ hỗ trợ crawler thu thập và index các trang hiệu quả hơn. Nhờ đó, khả năng crawl tổng thể của website được cải thiện, đây cũng là một yếu tố được công cụ tìm kiếm cân nhắc trong quá trình xếp hạng.
Tránh các vấn đề liên quan đến duplicate content
Nếu website tồn tại nhiều phiên bản của cùng một trang, chẳng hạn như phiên bản www và non-www, Google có thể index cả hai như những trang riêng biệt. Điều này dễ dẫn đến tình trạng trùng lặp nội dung và gây tác động tiêu cực đến SEO.
Kiểm soát cách nội dung website hiển thị trên kết quả tìm kiếm
Bằng cách chỉ định các trang nên hoặc không nên crawl trong robots.txt, bạn có thể định hướng việc thu thập dữ liệu để những trang mong muốn có cơ hội xuất hiện trên kết quả tìm kiếm. Điều này giúp kiểm soát cách nội dung website tiếp cận người dùng tiềm năng.
Giảm áp lực cho máy chủ
Khi website nhận nhiều yêu cầu từ crawler trong cùng một thời điểm, máy chủ có thể phải xử lý quá nhiều tác vụ, dẫn đến phản hồi chậm hoặc hoạt động kém ổn định. Việc xác định rõ những khu vực cần crawl trong robots.txt giúp hạn chế các yêu cầu không cần thiết, từ đó giảm áp lực cho máy chủ và cải thiện hiệu suất website.
Kiểm soát tốt hơn những nội dung được index
Robots.txt cho phép bạn ngăn crawler truy cập vào những trang không nên xuất hiện trên kết quả tìm kiếm, từ đó hạn chế việc index các nội dung không cần thiết hoặc mang tính nhạy cảm.
So Sánh Robots.txt Và Meta Directives
Robots.txt và meta directives đều được dùng để đưa ra chỉ dẫn cho crawler của công cụ tìm kiếm, nhưng phạm vi và cách hoạt động của hai thành phần này có sự khác biệt.
Robots.txt là một tệp được tạo và đặt trong thư mục gốc của website, dùng để cho crawler biết những khu vực nào trên website được phép crawl và những khu vực nào nên bỏ qua. Các chỉ dẫn trong robots.txt áp dụng ở phạm vi toàn website hoặc theo từng thư mục cụ thể.
Trong khi đó, meta directives là các thẻ HTML được chèn trực tiếp vào mã nguồn của từng trang riêng lẻ. Các thẻ này cho crawler biết liệu một trang cụ thể có nên được crawl hoặc index hay không.
Về bản chất, robots.txt mang tính định hướng và gợi ý hành vi crawl cho bot, còn meta directives đưa ra các chỉ dẫn rõ ràng và chi tiết hơn đối với việc crawl và index nội dung của từng trang. Ngoài ra, robots.txt kiểm soát hành vi crawl ở mức website hoặc thư mục, trong khi meta directives và x-robots cho phép kiểm soát việc index ở cấp độ từng trang riêng lẻ.
Các Yếu Tố Trong Một File Robots.txt
Một tệp robots.txt được tối ưu tốt có thể giúp cải thiện khả năng hiển thị của website trên kết quả tìm kiếm Google, đồng thời tránh việc các trang bị thuật toán đánh giá hoặc xử phạt ngoài ý muốn. Một tệp robots.txt gồm 5 thành phần chính:
- User-agent
- Disallow
- Allow
- Sitemap
- Crawl-delay
User Agent
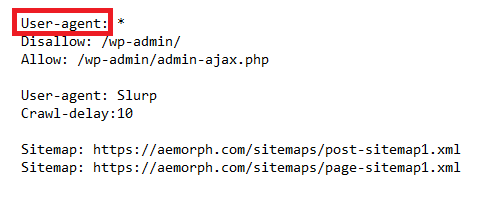
Trường user-agent trong robots.txt dùng để xác định những crawler nào được phép truy cập vào website. Trường này giúp hạn chế các crawler không mong muốn tiếp cận thông tin nhạy cảm hoặc kiểm soát quyền truy cập vào một số khu vực nhất định trên website. Bạn cần khai báo user-agent tương ứng với từng crawler mà bạn muốn cho phép hoặc giới hạn quyền truy cập.
Disallow

Việc thêm các chỉ thị disallow trong robots.txt cho crawler biết những khu vực nào trên website không được phép truy cập. Cách này thường được dùng để hạn chế việc crawl các trang bạn không muốn hiển thị trên SERPs, hoặc trong một số trường hợp là ngăn crawler index toàn bộ website.
Tuy nhiên, cần lưu ý rằng các chỉ thị trong robots.txt chỉ mang tính hướng dẫn và không có tính bắt buộc. Crawler vẫn có thể bỏ qua các chỉ thị này nếu chúng lựa chọn làm như vậy. Vì thế, dù disallow trong robots.txt có thể giúp giảm khả năng các trang không mong muốn xuất hiện trên SERPs, nhưng đây không phải là biện pháp đảm bảo tuyệt đối.
Allow
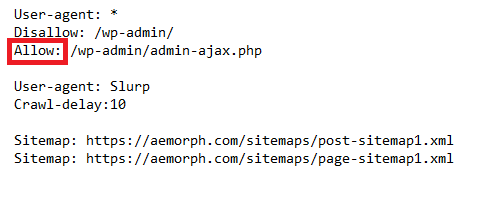
Chỉ thị allow trong robots.txt được dùng để xác định những khu vực nào trên website được phép cho crawler truy cập và những khu vực nào bị hạn chế. Chủ website có thể cho phép một số loại truy cập cụ thể bằng cách thêm chỉ thị allow. Khi được sử dụng cùng với disallow, allow giúp kiểm soát chi tiết hơn phạm vi mà crawler có thể crawl trên website.
Ví dụ, nếu website chỉ muốn cho phép bot của công cụ tìm kiếm crawl nội dung, chủ website có thể khai báo chỉ thị allow tương ứng. Ngược lại, trong trường hợp muốn chặn toàn bộ crawler, website sẽ sử dụng disallow cho tất cả các truy cập.
Khi crawler truy cập website, nó sẽ kiểm tra tệp robots.txt để xác định các giới hạn đối với nội dung được crawl. Nếu tồn tại chỉ thị allow áp dụng cho user-agent của crawler đó, crawler sẽ được phép truy cập vào khu vực tương ứng. Nếu không có chỉ thị allow, hoặc chỉ thị này dành cho user-agent khác, crawler sẽ không được phép truy cập vào khu vực đó.
Chỉ thị allow là một thành phần xuất hiện tương đối muộn trong robots.txt và chưa được hỗ trợ đồng nhất trên mọi nền tảng. Dù vậy, chỉ thị này ngày càng được sử dụng phổ biến hơn và đã được các công cụ tìm kiếm lớn hỗ trợ.
Sitemap
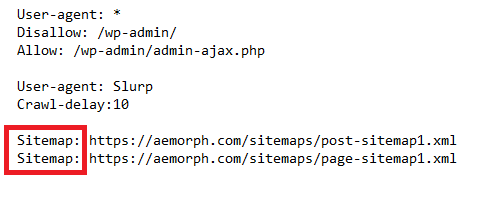
Sitemap là một tệp XML liệt kê các trang trên website. Bạn có thể khai báo sitemap trong robots.txt để crawler dễ dàng tìm thấy và crawl website hiệu quả hơn. Việc sử dụng sitemap đặc biệt quan trọng với các website có quy mô lớn, giúp crawler phát hiện đầy đủ các trang cần thu thập.
XML sitemap là một cách quan trọng để cho crawler biết những trang nào trên website là quan trọng nhất. Dựa vào thông tin này, crawler có thể crawl website có trọng tâm hơn và index các trang chính xác hơn.
Bạn có thể khai báo sitemap trong robots.txt theo hai cách. Cách thứ nhất là thêm trực tiếp đường dẫn sitemap vào nội dung của robots.txt. Cách thứ hai là đặt sitemap dưới dạng một tệp riêng biệt và chỉ rõ vị trí của tệp này trong robots.txt để crawler có thể truy cập.
Crawl-delay
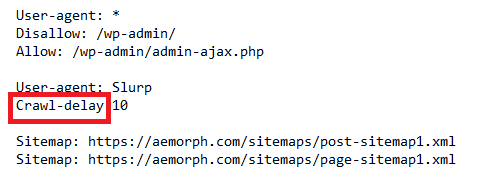
Crawl delay là một chỉ thị trong robots.txt dùng để cho crawler biết cần chờ bao lâu giữa các lần gửi yêu cầu đến cùng một website. Chỉ thị này thường được sử dụng khi bạn muốn giới hạn lượng truy cập từ crawler hoặc khi máy chủ không thể xử lý quá nhiều yêu cầu cùng lúc. Thời gian crawl delay được tính bằng giây.
Nhìn chung, crawl delay chỉ nên dùng ở mức cần thiết và trong những trường hợp thực sự phù hợp. Chỉ thị này có thể giúp kiểm soát lượng yêu cầu khi website nhận quá nhiều truy cập từ crawler, từ đó giảm áp lực cho máy chủ và cải thiện hiệu suất truy cập của người dùng thực. Bên cạnh đó, tệp robots.txt cũng nên được tổ chức rõ ràng, dễ theo dõi để crawler có thể nhận diện và tuân thủ các chỉ thị đã thiết lập.
Robots.txt Hoạt Động Như Thế Nào?
Robots.txt hoạt động như một “bản hướng dẫn truy cập” dành cho các công cụ tìm kiếm khi chúng ghé thăm website. Ngay khi một crawler tiếp cận website, nó sẽ tìm và đọc tệp robots.txt nằm ở thư mục gốc để hiểu những chỉ dẫn mà website đưa ra. Dựa trên các quy tắc được khai báo theo từng user-agent, crawler xác định những khu vực nào được phép crawl và những khu vực nào cần bỏ qua, từ đó quyết định phạm vi và cách thức thu thập dữ liệu. Nếu một đường dẫn bị chặn trong robots.txt, crawler sẽ không truy cập nội dung tại đó, giúp website tránh lãng phí tài nguyên crawl cho những trang không cần thiết. Nhờ cơ chế này, robots.txt hỗ trợ công cụ tìm kiếm crawl website có định hướng hơn, đồng thời giúp chủ website kiểm soát tốt hơn quá trình thu thập dữ liệu và phân bổ crawl budget.
Làm Thế Nào Để Tìm File Robots.txt Trên Website?
Thông thường có hai cách để bạn kiểm tra tệp robots.txt của một website.
Cách thứ nhất là kiểm tra trực tiếp trên front end. Bạn chỉ cần truy cập tên miền của website và thêm “/robots.txt” vào sau URL.
Ví dụ: https://aemorph.com/robots.txt
Cách thứ hai là kiểm tra ở phía backend. Tệp robots.txt có thể được tạo và quản lý thông qua các plugin SEO như Yoast SEO, Rank Math hoặc SEOPress.
Sau khi tìm thấy robots.txt, bạn có thể mở tệp này bằng trình soạn thảo văn bản để xem các quy tắc đã được thiết lập cho crawler. Nếu không tìm thấy robots.txt, hoặc tệp tồn tại nhưng không có nội dung, có thể hiểu rằng website không đặt ra quy tắc cụ thể nào và cho phép Google crawl và index toàn bộ nội dung.
Cách Tối Ưu Robots.txt Để SEO Hiệu Quả
Có một số nguyên tắc nên lưu ý khi tạo và quản lý tệp robots.txt. Việc áp dụng đúng các nguyên tắc này giúp người dùng dễ dàng tiếp cận thông tin cần thiết, đồng thời hỗ trợ Google crawl và index website một cách chính xác và hiệu quả hơn.
Hãy đảm bảo robots.txt dễ tìm
Crawler của công cụ tìm kiếm cần tìm thấy tệp robots.txt để biết những phần nào trên website được phép crawl và index. Nếu tệp này được đặt ở vị trí khó truy cập hoặc nội dung không rõ ràng, crawler có thể bỏ qua, dẫn đến việc index không đầy đủ các trang trên website. Để robots.txt dễ được phát hiện hơn, bạn có thể áp dụng một số cách đơn giản. Trước hết, có thể thêm liên kết đến robots.txt trong sitemap của website. Ngoài ra, bạn cũng có thể đặt liên kết này ở phần header hoặc footer. Cuối cùng, việc gửi trực tiếp robots.txt đến các công cụ tìm kiếm như Google và Bing cũng giúp đảm bảo tệp này được nhận diện đúng cách.
Kiểm tra lỗi và sai sót
Các lỗi trong robots.txt có thể khiến website không được Google index, hoặc nghiêm trọng hơn là bị hạn chế hiển thị. Vì vậy, việc kiểm tra robots.txt định kỳ để phát hiện và khắc phục lỗi là rất cần thiết. Bạn có thể sử dụng Google Search Console để kiểm tra, công cụ này sẽ quét robots.txt và thông báo nếu phát hiện vấn đề. Bên cạnh đó, các công cụ chuyên dụng như Robots.txt Validator cũng giúp kiểm tra tệp robots.txt và cung cấp báo cáo chi tiết về những lỗi còn tồn tại.
Lời Kết
Robots.txt giữ vai trò quan trọng trong việc kết nối website với công cụ tìm kiếm, giúp định hướng cách crawler tiếp cận và thu thập dữ liệu trên toàn bộ hệ thống trang. Trong tổng thể technical SEO, robots.txt không trực tiếp tạo ra thứ hạng, nhưng ảnh hưởng rõ rệt đến hiệu quả crawl, cách phân bổ crawl budget và khả năng công cụ tìm kiếm hiểu đúng cấu trúc website. Vì vậy, robots.txt cần được xem là một thành phần nền tảng của technical SEO và cần được kiểm soát, rà soát định kỳ để đảm bảo website luôn thân thiện với công cụ tìm kiếm.



