




ไฟล์ Robots.txt ควบคุมพฤติกรรมของเว็บครอว์เลอร์และบอทอัตโนมัติอื่นๆ ที่เยี่ยมชมเว็บไซต์ของคุณทั้งหมด
มันสำคัญเพราะช่วยปรับปรุงการทำงานด้านการเพิ่มประสิทธิภาพเว็บไซต์ (SEO) ของคุณโดยการมั่นใจว่าเพจที่ถูกต้องจะถูกจัดทำดัชนี
เรามาพูดถึงคำจำกัดความของมัน วิธีการทำงาน และวิธีที่คุณสามารถใช้เพื่อปรับปรุง SEO ของเว็บไซต์คุณ
Robots.txt คืออะไร
Robots.txt คือไฟล์ข้อความที่มีจุดประสงค์หลักในการบอกเว็บสไปเดอร์ว่าเพจใดในเว็บไซต์ทั้งหมดของคุณที่ควรให้เว็บครอว์เลอร์เข้าไปสำรวจและเพจใดที่ควรให้ข้ามไป
ไฟล์เหล่านี้มีจุดประสงค์หลักในการป้องกันไม่ให้เว็บครอว์เลอร์ทำให้เว็บไซต์ของคุณล้นด้วยคำขอเกินไป แต่ยังขจัดเพจอื่นๆ ออกจากการถูกสำรวจโดยสิ้นเชิง
คุณสามารถสร้างไฟล์ Robots.txt โดยใช้โปรแกรมแก้ไขข้อความใดก็ได้ แต่ต้องบันทึกไฟล์นั้นด้วยนามสกุล .TXT เมื่อคุณสร้างไฟล์ Robots.txt เสร็จแล้ว คุณต้องอัปโหลดมันไปยังไดเรกทอรีหลักของเว็บไซต์คุณ
เมื่อเว็บบอทเยี่ยมชมเว็บไซต์ของคุณทั้งหมด มันจะตรวจสอบการมีอยู่ของไฟล์ Robots.txt และใช้ข้อมูลภายในเพื่อกำหนดเพจที่ควรให้สำรวจและเพจที่ควรข้ามไป
หากคุณไม่มีไฟล์ Robots.txt เว็บครอว์เลอร์จะถือว่ามันสามารถสำรวจเพจที่สำคัญทั้งหมดในเว็บไซต์ของคุณได้
ทำไม Robots.txt ถึงสำคัญ
Robots.txt เป็นไฟล์ที่จำเป็นสำหรับเว็บไซต์ใดๆ ที่ต้องการเพิ่มประสิทธิภาพ SEO ของตน หากเว็บไซต์ของคุณยังไม่มีไฟล์ robots.txt เราขอแนะนำให้คุณสร้างไฟล์นี้ขึ้นมา
นี่คือเหตุผลที่ Robots.txt มีความสำคัญสำหรับ SEO ของเว็บไซต์คุณ:
มันช่วยปรับปรุงความสามารถในการสำรวจเว็บไซต์ของคุณ
เมื่อคุณมี robots.txt ที่ได้รับการปรับแต่งอย่างดี มันจะช่วยให้เว็บบอทสามารถจัดทำดัชนีเพจของคุณได้อย่างมีประสิทธิภาพมากขึ้น ซึ่งจะช่วยปรับปรุงความสามารถในการสำรวจเว็บไซต์ของคุณ โดยที่เป็นปัจจัยที่เครื่องมือค้นหาอื่นๆ นำมาพิจารณาในการจัดอันดับเว็บไซต์
มันช่วยหลีกเลี่ยงปัญหาคอนเทนต์ซ้ำ
หากมีหลายเวอร์ชันของเพจเดียวกันในเว็บไซต์ของคุณ (เช่น เวอร์ชันที่มี www และเวอร์ชันที่ไม่มี www) Google อาจจัดทำดัชนีทั้งสองเวอร์ชันเป็นเพจที่แตกต่างกัน ซึ่งอาจสร้างปัญหาคอนเทนต์ซ้ำ และส่งผลเสียต่อ SEO ของคุณ
มันช่วยควบคุมวิธีการนำเสนอคอนเทนต์ของเว็บไซต์ในผลการค้นหา
โดยการระบุเวอร์ชันที่ต้องการของเพจใน robots.txt คุณสามารถช่วยให้มั่นใจว่าเพจเหล่านั้นคือเพจที่จะแสดงในผลการค้นหา มันช่วยควบคุมวิธีที่คอนเทนต์ของเว็บไซต์ของคุณนำเสนอให้กับผู้เยี่ยมชมที่มีศักยภาพ
มันช่วยจัดการโหลดของเซิร์ฟเวอร์
หากเว็บไซต์ของคุณได้รับการเข้าชมมากจากเว็บครอว์เลอร์ มันอาจทำให้ทรัพยากรของเซิร์ฟเวอร์เว็บไซต์คุณถูกใช้มากเกินไป โดยการระบุเพจที่ต้องการให้ครอว์เลอร์สำรวจใน robots.txt คุณสามารถช่วยลดภาระบนเซิร์ฟเวอร์เว็บไซต์และปรับปรุงประสิทธิภาพเว็บไซต์ได้
มันให้คุณควบคุมสิ่งที่ถูกจัดทำดัชนีได้มากขึ้น
คุณสามารถระบุใน robots.txt เพจที่คุณไม่ต้องการให้มีการจัดทำดัชนีได้ ซึ่งจะช่วยป้องกันไม่ให้เครื่องมือค้นหาจัดทำดัชนีและแสดงข้อมูลที่อ่อนไหวใน SERPs
ส่วนประกอบของไฟล์ Robots.txt
ไฟล์ Robots.txt ที่ได้รับการปรับแต่งอย่างดีสามารถช่วยปรับปรุงการมองเห็นของเว็บไซต์ของคุณในผลการค้นหาของ Google และป้องกันไม่ให้เพจของคุณถูกลงโทษโดยอัลกอริธึมโดยไม่ตั้งใจ
ไฟล์ Robots.txt ประกอบด้วยส่วนหลัก 5 ส่วน:
1) User-agent
2) Disallow
3) Allow
4) Sitemap
5) Crawl-delay
User Agent
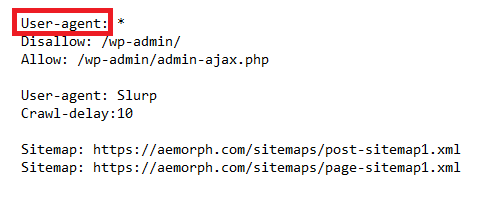
ฟิลด์ user-agent ใน robots.txt ระบุว่าเว็บบอทใดบ้างที่ได้รับอนุญาตให้เข้าถึงเว็บไซต์
User-agent ป้องกันไม่ให้เว็บบอทที่เป็นอันตรายเข้าถึงข้อมูลที่ละเอียดอ่อนในเว็บไซต์หรือจำกัดการเข้าถึงบางส่วนของเว็บไซต์
คุณต้องระบุฟิลด์ user-agent สำหรับแต่ละเว็บบอทที่ได้รับอนุญาตให้เข้าถึง
Disallow

การเพิ่มคำสั่ง “disallow” ใน robots.txt จะบอกให้ครอว์เลอร์ทราบว่าไม่อนุญาตให้เข้าถึงส่วนใดของเว็บไซต์
บอทจะไม่เข้าถึงเพจในเว็บไซต์ที่คุณไม่ต้องการให้แสดงในผลการค้นหาหรือถ้าคุณต้องการป้องกันไม่ให้เว็บบอทจัดทำดัชนีเว็บไซต์ของคุณทั้งหมด
สิ่งสำคัญที่ต้องจำไว้คือคำสั่งใน robots.txt เป็นเพียงคำแนะนำ – มันไม่สามารถบังคับได้และครอว์เลอร์สามารถเลือกที่จะไม่สนใจคำสั่งเหล่านั้นได้
ดังนั้น แม้ว่าการห้ามไม่ให้เพจปรากฏในไฟล์ robots.txt อาจช่วยป้องกันไม่ให้พวกมันปรากฏในผลการค้นหาก็ตาม แต่มันไม่รับประกัน
Allow
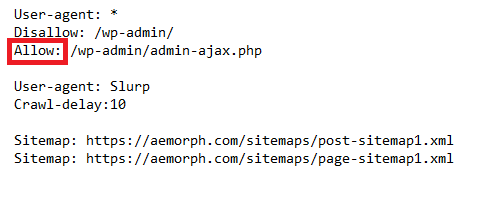
คำสั่ง “allow” ใน robots.txt ระบุส่วนใดของเว็บไซต์ที่เปิดให้เว็บบอทเข้าถึงและส่วนใดที่ไม่อนุญาต
เจ้าของเว็บไซต์สามารถอนุญาตให้มีการเข้าชมบางประเภทได้โดยการเพิ่มคำสั่ง allow
คำสั่ง allow ที่ใช้ร่วมกับคำสั่ง disallow ให้การควบคุมที่ละเอียดเกี่ยวกับส่วนของเว็บไซต์ที่เข้าถึงได้สำหรับครอว์เลอร์
ตัวอย่างเช่น หากเว็บไซต์ต้องการอนุญาตให้เฉพาะบอทเครื่องมือค้นหาจัดทำดัชนีเนื้อหาของเว็บไซต์ จะรวมคำสั่ง allow ที่ระบุให้ทำเช่นนั้น แต่หากเว็บไซต์ต้องการบล็อกครอว์เลอร์ทั้งหมด ก็จะใช้คำสั่ง disallow สำหรับการเข้าชมทั้งหมด
เมื่อเว็บบอทเยี่ยมชมเว็บไซต์ มันจะตรวจสอบไฟล์ robots.txt เพื่อตรวจสอบว่ามีข้อจำกัดใดบ้างเกี่ยวกับสิ่งที่สามารถสำรวจได้ หากมีคำสั่ง allow สำหรับ user-agent ของครอว์เลอร์ บอทนั้นก็จะสามารถเข้าถึงส่วนที่กำหนดของเว็บไซต์ได้
หากไม่มีคำสั่ง allow หรือคำสั่งดังกล่าวเป็นของ user-agent อื่นๆ บอทนั้นจะไม่สามารถเข้าถึงส่วนที่ระบุของเว็บไซต์ได้
คำสั่ง allow เป็นฟีเจอร์ใหม่ในไฟล์ robots.txt และยังไม่ได้รับการรองรับอย่างเต็มที่ในทุกเว็บไซต์ แต่ก็ได้รับความนิยมมากขึ้นและได้รับการรองรับจากเครื่องมือค้นหาหลักๆ ทั้งหมด
Sitemap
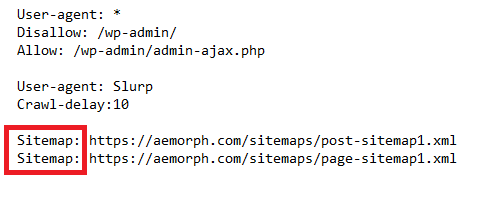
Sitemap คือไฟล์ XML ที่บอกลิสต์เพจทั้งหมดในเว็บไซต์ของคุณ
คุณสามารถเพิ่ม Sitemap ลงในไฟล์ robots.txt เพื่อให้ครอว์เลอร์สามารถหามันและสำรวจเว็บไซต์ของคุณได้อย่างมีประสิทธิภาพมากขึ้น การใช้ Sitemap เป็นสิ่งสำคัญหากเว็บไซต์ของคุณมีจำนวนเพจมาก
XML Sitemap เป็นวิธีที่สำคัญในการบอกครอว์เลอร์ว่าเพจไหนในเว็บไซต์ของคุณที่สำคัญที่สุด ซึ่งจะช่วยให้มันสำรวจเว็บไซต์ได้อย่างมีประสิทธิภาพและจัดทำดัชนีเพจได้อย่างถูกต้อง
คุณสามารถเพิ่ม Sitemap ในไฟล์ robots.txt ของคุณได้ 2 วิธี คือ สามารถรวมไว้ในไฟล์ robots.txt เดียวกันหรือเพิ่มเป็นไฟล์แยกต่างหาก หากเพิ่มเป็นไฟล์แยกคุณต้องระบุที่ตั้งของไฟล์ใน robots.txt เพื่อให้ครอว์เลอร์หามันเจอ
Crawl-delay
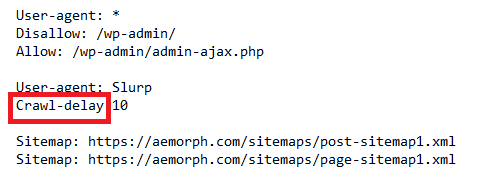
Crawl-delay คือคำสั่งในไฟล์ robots.txt ที่บอกให้ครอว์เลอร์รอระหว่างคำขอไปยังเว็บไซต์เดียวกัน ซึ่งอาจมีประโยชน์หากคุณต้องการจำกัดปริมาณการเข้าชมเว็บไซต์ของคุณหรือหากเซิร์ฟเวอร์ของคุณไม่สามารถรองรับคำขอหลายๆ รายการพร้อมกันได้ – crawl-delay จะใช้หน่วยเป็นวินาที
โดยทั่วไปแล้วควรใช้คำสั่ง crawl-delay อย่างระมัดระวังและเฉพาะเมื่อจำเป็นเท่านั้น มันสามารถช่วยลดปริมาณการเข้าชมจากครอว์เลอร์ถ้าเว็บไซต์ของคุณได้รับการเข้าชมมากเกินไป
มันจะช่วยลดภาระบนเซิร์ฟเวอร์และปรับปรุงประสิทธิภาพของเว็บไซต์สำหรับผู้เยี่ยมชมทั่วไป
คุณควรทำให้ไฟล์ robots.txt ของคุณมีระเบียบและเข้าใจง่ายเพื่อให้ครอว์เลอร์สามารถค้นหาและปฏิบัติตามคำสั่งได้อย่างง่ายดาย
วิธีการทำงานของ robots.txt
ไฟล์ robots.txt จะบอกเว็บบอท (ที่รู้จักกันในชื่อครอว์เลอร์หรือสไปเดอร์) ว่าควรสำรวจเพจใดและเพจใดควรละเว้น ไฟล์นี้เป็นส่วนหนึ่งของมาตรฐานการยกเว้นบอทที่เรียกว่า Robots Exclusion Protocol
ไฟล์ robots.txt จะอยู่ในไดเรกทอรีหลักของเว็บไซต์ของคุณ สำหรับบอทที่จะสำรวจเว็บไซต์ของคุณได้ มันต้องสามารถหาฟีล์ robots.txt ได้ จากนั้นบอทจะอ่านไฟล์และทำตามคำแนะนำที่คุณได้ให้ไว้
ไฟล์ robots.txt ไม่จำเป็นต้องมี แต่การมีไฟล์นี้ถือเป็นความคิดที่ดี มันเป็นวิธีง่ายๆ ในการบอกบอทของเครื่องมือค้นหาว่าคุณต้องการให้พวกมันสำรวจอะไรในเว็บไซต์ของคุณและอะไรที่ไม่ต้องการให้สำรวจ
คุณจะหาฟีล์ robots.txt ในเว็บไซต์ของคุณได้อย่างไร
โดยทั่วไปมีสองวิธีที่คุณสามารถหาฟีล์ robots.txt สำหรับเว็บไซต์ได้
วิธีแรกคือการหาฟีล์ robots.txt บนฟรอนต์เอนด์ เพียงแค่ไปที่โดเมนของคุณแล้วเพิ่ม “/robots.txt” ลงไป
ตัวอย่างเช่น: https://aemorph.com/robots.txt
วิธีที่สองคือการหาฟีล์ robots.txt ในแบ็กเอนด์ คุณอาจพบมันในปลั๊กอินบางตัว เช่น Yoast SEO, Rankmath, SEO press ฯลฯ
เมื่อคุณพบไฟล์ robots.txt แล้ว ให้เปิดมันในตัวแก้ไขข้อความ และคุณจะสามารถเห็นกฎที่ตั้งไว้สำหรับครอว์เลอร์
หากคุณไม่พบไฟล์ robots.txt หรือไฟล์นั้นว่างเปล่า หมายความว่าเว็บไซต์นั้นไม่น่าจะมีการตั้งกฎเฉพาะสำหรับครอว์เลอร์
ในกรณีนี้ คุณควรถือว่าเว็บไซต์นั้นเปิดให้ครอว์เลอร์สำรวจและจัดทำดัชนีได้
แนวทางปฏิบัติที่ดีที่สุดสำหรับ SEO
มีแนวทางปฏิบัติที่ดีที่สุดเมื่อสร้างและจัดการไฟล์ robots.txt ของคุณ
โดยการปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุด คุณสามารถมั่นใจได้ว่า ผู้เยี่ยมชมสามารถค้นหาข้อมูลที่ต้องการได้และ Google จัดทำดัชนีเว็บไซต์ของคุณอย่างถูกต้อง
ทำให้ไฟล์ Robots.txt ของคุณหาง่าย
ครอว์เลอร์ของเครื่องมือค้นหาต้องสามารถหาฟีล์เพื่อที่จะรู้ว่าจะสำรวจและจัดทำดัชนีส่วนใดของเว็บไซต์ของคุณ
หากไฟล์นั้นถูกซ่อนหรือเข้าใจยาก ครอว์เลอร์อาจพลาดไปทั้งหมดและจัดทำดัชนีเนื้อหาของคุณน้อยลง
หากคุณต้องการทำให้ไฟล์ robots.txt ของคุณหาง่ายขึ้น มีหลายสิ่งที่คุณสามารถทำได้
เริ่มต้นด้วยการรวมลิงก์ไปยังมันในแผนผังเว็บไซต์ของคุณ นอกจากนี้คุณยังสามารถเพิ่มลิงก์ไปยังมันในส่วนหัวหรือส่วนท้ายของเว็บไซต์ของคุณ
สุดท้ายคุณสามารถส่งไฟล์ robots.txt ของคุณไปยังเครื่องมือค้นหาต่างๆ เช่น Google และ Bing
ตรวจสอบข้อผิดพลาด
ข้อผิดพลาดในไฟล์ robots.txt อาจทำให้เว็บไซต์ของคุณไม่ได้รับการจัดทำดัชนีจาก Google หรือแย่กว่านั้นคือถูกขึ้นบัญชีดำ การตรวจสอบไฟล์ robots.txt ของคุณเพื่อหาข้อผิดพลาดและข้อบกพร่องเป็นสิ่งสำคัญ
วิธีหนึ่งในการตรวจสอบข้อผิดพลาดในไฟล์ robots.txt คือการใช้ Google Webmaster Tools เครื่องมือของ Google จะสแกนไฟล์ robots.txt ของคุณและรายงานข้อผิดพลาดที่พบ
อีกวิธีหนึ่งในการตรวจสอบข้อผิดพลาดในไฟล์ robots.txt คือการใช้เครื่องมือเช่น Robots.txt Validator เครื่องมือนี้จะสแกนไฟล์ robots.txt ของคุณและรายงานข้อผิดพลาดใดๆ
Robots.txt vs Meta Directives
ไฟล์ robots.txt มีคำแนะนำสำหรับครอว์เลอร์ของเครื่องมือค้นหา เป็นไฟล์ที่คุณสามารถสร้างและอัปโหลดไปยังไดเรกทอรีหลักของเว็บไซต์ของคุณ เพื่อบอกว่าหน้าไหนของเว็บไซต์คุณควรและไม่ควรจะถูกสำรวจ
ในทางกลับกัน Meta Directives คือแท็ก HTML ที่คุณสามารถแทรกลงในรหัสของแต่ละหน้าในเว็บไซต์ของคุณ แท็กเหล่านี้ก็ใช้บอกครอว์เลอร์ของเครื่องมือค้นหาว่าควรสำรวจหน้าไหนและหน้าไหนควรละเว้น
ไฟล์ robots.txt ให้คำแนะนำแก่บอท ในขณะที่ Meta Directives ให้คำแนะนำที่ชัดเจนและมีความแน่นอนมากขึ้น



