




Khi website có quy mô lớn hoặc tăng trưởng nội dung nhanh, nhiều doanh nghiệp bắt đầu quan tâm đến crawl budget và lý do vì sao Google không index hết tất cả các trang. Việc nội dung quan trọng bị chậm index hoặc không được thu thập dữ liệu có thể ảnh hưởng trực tiếp đến hiệu suất SEO tổng thể. Hiểu rõ cách crawl budget vận hành sẽ giúp doanh nghiệp kiểm soát tốt hơn khả năng hiển thị, phân bổ tài nguyên hợp lý và cải thiện tốc độ index cho các trang mang giá trị cao.
Crawl Budget Là Gì?
Crawl budget là lượng tài nguyên mà Google phân bổ để thu thập dữ liệu trên một website trong một khoảng thời gian nhất định. Mỗi website đều có giới hạn crawl budget riêng, phụ thuộc vào nhiều yếu tố như quy mô, hiệu suất máy chủ và mức độ uy tín. Khi crawl budget bị sử dụng không hiệu quả, Google có thể bỏ qua các trang quan trọng, khiến nội dung mới hoặc nội dung chiến lược không được index kịp thời. Đây là lý do crawl budget đặc biệt quan trọng với các website lớn, trang thương mại điện tử hoặc website có cấu trúc phức tạp.

Mối Quan Hệ Giữa Crawl Budget Và Indexing
Crawl là điều kiện tiên quyết để index. Nếu Google không crawl được trang, trang đó sẽ không thể xuất hiện trong chỉ mục tìm kiếm. Khi crawl budget bị tiêu tốn vào các trang không quan trọng, quá trình index các trang giá trị sẽ bị chậm lại. Điều này ảnh hưởng trực tiếp đến khả năng hiển thị và hiệu quả SEO của website.
Website Nào Cần Quan Tâm Đến Crawl Budget
Không phải website nào cũng gặp vấn đề nghiêm trọng về crawl budget. Tuy nhiên, các website có hàng nghìn trang, nhiều URL tham số, nội dung lọc hoặc phân trang cần đặc biệt chú ý. Với những website này, tối ưu crawl budget giúp Google tập trung vào các trang quan trọng và cải thiện hiệu suất SEO tổng thể.
Cách Google Phân Bổ Crawl Budget Cho Website
Google xác định crawl budget dựa trên hai yếu tố chính là crawl rate limit và crawl demand. Crawl rate limit phản ánh khả năng chịu tải của máy chủ, trong khi crawl demand liên quan đến mức độ Google muốn thu thập dữ liệu từ website. Khi website có nội dung chất lượng, được cập nhật thường xuyên và có tín hiệu tốt, Google có xu hướng ưu tiên crawl nhiều hơn. Ngược lại, website có nhiều trang trùng lặp hoặc lỗi kỹ thuật sẽ bị giảm mức độ thu thập.
Google không phân bổ crawl budget theo một hạn mức cố định cho từng website, mà điều chỉnh linh hoạt dựa trên cách Googlebot tương tác với website đó theo thời gian. Crawl budget thực chất là kết quả của nhiều quyết định nhỏ mà Google đưa ra nhằm cân bằng giữa việc thu thập thông tin mới và việc sử dụng tài nguyên crawl một cách hiệu quả.
Các Yếu Tố Ảnh Hưởng Đến Crawl Budget
Crawl budget không phải là một con số cố định mà thay đổi liên tục dựa trên cách Google đánh giá website. Việc hiểu rõ các yếu tố ảnh hưởng giúp doanh nghiệp xác định đúng nguyên nhân khiến Google crawl kém hiệu quả và có hướng tối ưu phù hợp. Dưới đây là những yếu tố quan trọng nhất tác động trực tiếp đến crawl budget của một website.
Quy mô và số lượng URL của website
Website càng có nhiều URL thì crawl budget càng bị phân tán. Google cần phân bổ tài nguyên để thu thập dữ liệu trên toàn bộ website, nên số lượng URL lớn làm tăng khả năng Google không crawl hết tất cả các trang. Điều này đặc biệt rõ ràng với website TMĐT, trang lọc sản phẩm hoặc website có nhiều URL sinh ra tự động. Nếu không kiểm soát tốt cấu trúc URL, nhiều trang kém giá trị sẽ tiêu tốn crawl budget cần thiết cho các trang quan trọng.
Chất lượng và giá trị nội dung của các trang
Google ưu tiên crawl những trang có nội dung chất lượng, hữu ích và được cập nhật thường xuyên. Các trang mỏng nội dung, trùng lặp hoặc ít giá trị sẽ dần bị crawl ít hơn theo thời gian. Khi website có nhiều trang chất lượng thấp, Google có xu hướng giảm mức độ crawl tổng thể. Ngược lại, website có tỷ lệ trang hữu ích cao thường được crawl đều đặn và ổn định hơn.
Tốc độ tải trang và khả năng phản hồi của máy chủ
Hiệu suất máy chủ ảnh hưởng trực tiếp đến crawl budget. Nếu máy chủ phản hồi chậm, thường xuyên lỗi hoặc timeout, Googlebot sẽ giảm tốc độ crawl để tránh gây quá tải. Điều này làm giảm số lượng trang được crawl trong mỗi phiên. Website có tốc độ ổn định, phản hồi nhanh và ít lỗi sẽ cho phép Google crawl nhiều URL hơn trong cùng một khoảng thời gian.
Cấu trúc website và internal linking
Cấu trúc website rõ ràng giúp Googlebot dễ dàng khám phá và ưu tiên các trang quan trọng. Internal linking hợp lý giúp Google hiểu đâu là trang chính, đâu là trang phụ, từ đó phân bổ crawl budget hiệu quả hơn. Ngược lại, cấu trúc rối, nhiều trang mồ côi hoặc liên kết nội bộ không logic khiến Google khó xác định ưu tiên crawl. Điều này làm giảm khả năng các trang quan trọng được crawl thường xuyên.
Tình trạng trùng lặp nội dung và URL
Nội dung trùng lặp và nhiều URL dẫn đến cùng một nội dung làm lãng phí crawl budget. Googlebot phải crawl nhiều URL nhưng không thu được giá trị mới. Các tham số URL, phân trang, bộ lọc và phiên bản URL khác nhau là nguyên nhân phổ biến. Nếu không được kiểm soát bằng canonical, noindex hoặc cấu trúc URL hợp lý, crawl budget sẽ bị tiêu tốn vào các trang không cần thiết.
File robots.txt và thẻ meta robots
Robots.txt và meta robots ảnh hưởng đến việc Googlebot có được phép crawl một số khu vực hay không. Việc chặn đúng các trang không quan trọng giúp tiết kiệm crawl budget cho những trang cần index. Tuy nhiên, chặn sai hoặc quá mức có thể khiến Google không crawl được các trang giá trị. Doanh nghiệp cần sử dụng robots.txt như một công cụ kiểm soát crawl, không phải công cụ xử lý index.
Sitemap XML và mức độ cập nhật
Sitemap XML giúp Googlebot nhận biết những URL quan trọng cần được crawl. Sitemap được cập nhật thường xuyên với các URL hợp lệ giúp Google phân bổ crawl budget hiệu quả hơn. Ngược lại, sitemap chứa nhiều URL lỗi, chuyển hướng hoặc noindex khiến Googlebot lãng phí tài nguyên. Sitemap không tạo thêm crawl budget, nhưng giúp Google sử dụng crawl budget hiện có đúng cách.
Tần suất cập nhật nội dung trên website
Website thường xuyên cập nhật nội dung mới hoặc chỉnh sửa nội dung cũ có xu hướng được crawl thường xuyên hơn. Googlebot ưu tiên những website có dấu hiệu hoạt động và thay đổi liên tục. Website ít cập nhật hoặc gần như tĩnh sẽ dần bị crawl ít hơn theo thời gian. Việc duy trì nhịp cập nhật hợp lý giúp giữ crawl budget ổn định và hiệu quả.
Tình trạng lỗi HTTP và chuyển hướng
Các lỗi như 404, 500 hoặc chuỗi redirect dài làm tiêu tốn crawl budget mà không mang lại giá trị. Googlebot phải xử lý nhiều yêu cầu không thành công trước khi đến được nội dung thực. Nếu lỗi xuất hiện thường xuyên, Google sẽ giảm mức độ crawl để tránh lãng phí tài nguyên. Việc kiểm soát lỗi và tối ưu chuyển hướng giúp crawl budget được sử dụng hiệu quả hơn.
Mức độ uy tín và lịch sử crawl của website
Website có lịch sử ổn định, ít lỗi và nội dung chất lượng thường được Google tin tưởng hơn trong việc phân bổ crawl budget. Các website mới hoặc từng gặp nhiều vấn đề kỹ thuật sẽ cần thời gian để Google điều chỉnh lại mức độ crawl. Uy tín không phải yếu tố duy nhất, nhưng ảnh hưởng đến cách Googlebot ưu tiên tài nguyên crawl trong dài hạn.
Hướng Dẫn Kiểm Tra Crawl Budget Trong Google Search Console
Bạn vào Google Search Console → Settings → Crawl stats. Đây là báo cáo phản ánh trực tiếp cách Googlebot crawl website theo thời gian. Google không cho một con số crawl budget cố định, nên bạn sẽ đọc crawl budget thông qua các chỉ số ở báo cáo này.
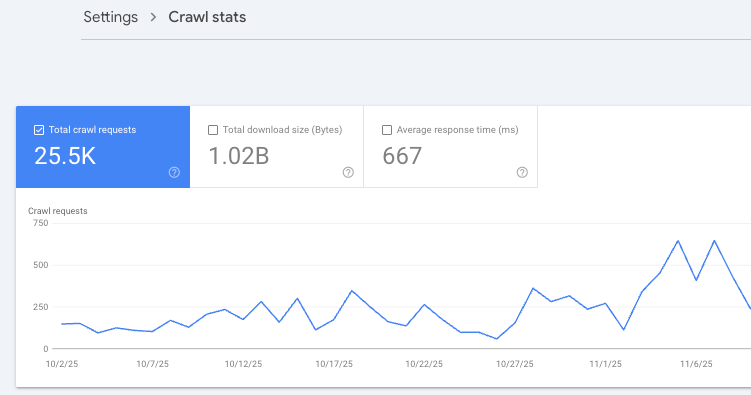
Trong báo cáo Crawl stats, bạn sẽ cần đọc hiểu một số chỉ số sau:
- Crawl requests (số lượt yêu cầu crawl): Chỉ số này phản ánh Googlebot ghé website bạn bao nhiêu lần trong một khoảng thời gian và xu hướng tăng/giảm ra sao. Nếu website có nhiều trang nhưng crawl requests thấp hoặc giảm dần, thường nghĩa là Googlebot đang crawl ít hơn và khả năng cập nhật/index sẽ chậm hơn, đặc biệt với website lớn hoặc nhiều URL mới.
- Average response time (thời gian phản hồi trung bình): Đây là chỉ số cho biết máy chủ của bạn phản hồi nhanh hay chậm khi Googlebot truy cập. Nếu response time cao và tăng kéo dài, Google thường tự giảm tốc độ crawl để tránh gây tải cho website. Nói đơn giản, website phản hồi chậm thì crawl budget thực tế sẽ bị “siết” lại.
- Total download size (tổng dung lượng tải về): Chỉ số này cho biết Googlebot đã tải bao nhiêu dữ liệu khi crawl. Nếu crawl requests có nhưng download size rất thấp hoặc giảm mạnh, có thể Google đang crawl nhiều URL nhẹ/không nhiều nội dung, hoặc gặp nhiều redirect/lỗi khiến không tải được nội dung thực. Nó giúp bạn phát hiện crawl “không hiệu quả” chứ không chỉ crawl “nhiều hay ít”.
- Response codes và file type. Response codes cho biết Googlebot gặp bao nhiêu yêu cầu thành công (200) và bao nhiêu yêu cầu lỗi/redirect (3xx/4xx/5xx). Nếu tỷ lệ 3xx/4xx/5xx cao, crawl budget bị tiêu hao vào lỗi và chuyển hướng thay vì nội dung cần index. File type giúp bạn thấy Google đang crawl chủ yếu HTML (trang nội dung) hay đang tiêu tốn vào JS/CSS/image quá nhiều, từ đó hiểu crawl đang “đổ vào đâu”.
- Googlebot Type:phản ánh loại Googlebot đang hoạt động trên website. Page resource load chiếm tỷ lệ cao cho thấy Googlebot đang tải tài nguyên để render trang. Smartphone bot chiếm ưu thế là tín hiệu bình thường trong mobile-first indexing. Nếu Page resource load quá cao nhưng tốc độ index chậm, crawl budget đang bị tiêu hao vào quá trình render thay vì thu thập nội dung.
- By Purpose: cho biết mục đích crawl của Googlebot. Refresh chiếm đa số nghĩa là Google đang quay lại các URL đã biết. Discovery thấp cho thấy Google ít khám phá URL mới. Với website đang phát triển hoặc thường xuyên xuất bản nội dung mới, Discovery quá thấp là dấu hiệu crawl budget không đủ để mở rộng phạm vi index.
Sau khi xem Crawl stats, bạn chuyển sang Indexing → Pages. Ở đây, bạn cần nhìn 2 trạng thái: Discovered – currently not indexed (Google biết URL nhưng chưa crawl/index) và Crawled – currently not indexed (đã crawl nhưng chưa index). Nếu hai nhóm này tăng cao, đặc biệt với URL quan trọng, thường là dấu hiệu website đang bị phân bổ crawl không tốt hoặc có quá nhiều URL khiến Google ưu tiên thấp.
Bạn chỉ cần trả lời 3 câu hỏi để kết luận tình trạng crawl budget:
- Googlebot có crawl đều không (crawl requests ổn định/tăng)?
- Website có cản trở Googlebot không (response time và tỷ lệ lỗi)?
- Crawl có chuyển thành index không (Discovered/Crawled not indexed)?
Nếu một trong ba câu trả lời là không, bạn đã xác định được website đang có vấn đề liên quan đến crawl budget hoặc phân bổ crawl.
Hướng Dẫn Tối Ưu Crawl Budget Để Tăng Index Hiệu Quả
Tối ưu crawl budget không phải là tăng số lượt Googlebot truy cập một cách cơ học, mà là giúp Google sử dụng nguồn lực thu thập dữ liệu đúng chỗ. Khi crawl budget được phân bổ hợp lý, các trang quan trọng sẽ được crawl và index nhanh hơn, trong khi các trang không mang giá trị SEO sẽ bị hạn chế. Đây là bước then chốt giúp website cải thiện khả năng hiển thị một cách bền vững.
Kiểm soát và loại bỏ các URL không mang giá trị index
Bước quan trọng nhất trong tối ưu crawl budget không phải tăng crawl, mà là giảm crawl lãng phí. Website cần xác định rõ các nhóm URL không cần index như trang lọc, tham số URL, trang tìm kiếm nội bộ, phân trang dư thừa hoặc các biến thể URL sinh tự động. Những URL này nếu không được kiểm soát sẽ tiêu tốn crawl budget của các trang quan trọng. Doanh nghiệp cần sử dụng robots.txt, noindex hoặc cấu trúc URL hợp lý để ngăn Googlebot truy cập những khu vực không cần thiết.
Ưu tiên crawl cho các trang quan trọng bằng cấu trúc internal linking
Googlebot khám phá website thông qua liên kết nội bộ, vì vậy internal linking là công cụ định hướng crawl hiệu quả nhất. Các trang chiến lược như danh mục, sản phẩm chủ lực hoặc bài viết trụ cột cần được đặt ở vị trí dễ truy cập và có nhiều internal link trỏ về. Ngược lại, các trang phụ hoặc ít giá trị không nên được liên kết quá nhiều. Khi internal linking rõ ràng, Googlebot hiểu đâu là trang cần ưu tiên crawl thường xuyên để cập nhật nội dung.
Giảm thiểu trùng lặp URL và nội dung
Trùng lặp là nguyên nhân lớn nhất gây lãng phí crawl budget. Một nội dung nhưng tồn tại nhiều URL khác nhau khiến Googlebot phải crawl lặp lại mà không thu được giá trị mới. Website cần xử lý triệt để bằng canonical chính xác, chuẩn hóa URL, hạn chế tham số không cần thiết và tránh tạo nhiều phiên bản nội dung tương tự. Khi mỗi URL đại diện cho một nội dung rõ ràng, crawl budget được sử dụng hiệu quả hơn và quá trình index diễn ra nhanh hơn.
Tối ưu sitemap XML để hướng Googlebot đúng URL
Sitemap không làm tăng crawl budget nhưng giúp Google sử dụng crawl budget đúng chỗ. Sitemap XML chỉ nên chứa các URL có giá trị index, trạng thái HTTP 200 và không bị chặn index. Sitemap cần được cập nhật thường xuyên khi có nội dung mới hoặc thay đổi cấu trúc URL. Một sitemap sạch giúp Googlebot nhanh chóng phát hiện và ưu tiên crawl những trang quan trọng, đặc biệt là nội dung mới hoặc nội dung vừa được cập nhật.
Cải thiện tốc độ tải trang và độ ổn định máy chủ
Crawl budget chịu ảnh hưởng trực tiếp từ khả năng phản hồi của máy chủ. Nếu server chậm, lỗi nhiều hoặc không ổn định, Googlebot sẽ tự giảm tốc độ crawl để tránh gây quá tải. Website cần đảm bảo thời gian phản hồi thấp, hạn chế lỗi 5xx và tối ưu tài nguyên tải trang. Khi máy chủ hoạt động ổn định, Googlebot có thể crawl nhiều URL hơn trong cùng một khoảng thời gian, từ đó tăng khả năng index.
Xử lý lỗi HTTP và chuỗi redirect không cần thiết
Các lỗi 404, 410 hoặc redirect nhiều bước khiến crawl budget bị tiêu hao mà không mang lại nội dung mới. Website cần rà soát và xử lý các URL lỗi, xóa bỏ trang không còn giá trị hoặc chuyển hướng gọn gàng về URL phù hợp nhất. Redirect nên được giữ ở mức tối thiểu và tránh chuỗi redirect dài. Khi Googlebot ít gặp lỗi, crawl budget được dùng cho các trang cần index thay vì xử lý các vấn đề kỹ thuật.
Tăng tín hiệu chất lượng và tần suất cập nhật nội dung
Google ưu tiên crawl những website có dấu hiệu hoạt động và giá trị thông tin rõ ràng. Việc cập nhật nội dung cũ, bổ sung thông tin mới và duy trì nhịp xuất bản hợp lý giúp Googlebot quay lại thường xuyên hơn. Nội dung chất lượng cao làm tăng khả năng Google đánh giá website đáng để crawl đều đặn. Đây là yếu tố mang tính dài hạn nhưng ảnh hưởng rõ rệt đến hiệu quả index.
Theo dõi crawl budget bằng dữ liệu thực tế
Để tối ưu đúng hướng, website cần theo dõi crawl budget thông qua Google Search Console và log server. Crawl Stats giúp đánh giá số lượng request, lỗi và tốc độ crawl, trong khi log server cho biết Googlebot đang thực sự crawl những URL nào. Dựa trên dữ liệu này, doanh nghiệp có thể điều chỉnh robots, internal link và cấu trúc URL một cách chính xác. Tối ưu crawl budget không phải hành động một lần mà là quá trình liên tục.
Lời Kết
Crawl budget là yếu tố nền tảng của technical SEO và ảnh hưởng trực tiếp đến khả năng index của website. Khi hiểu rõ crawl budget vận hành như thế nào và triển khai các biện pháp tối ưu phù hợp, doanh nghiệp có thể giúp Google tập trung thu thập dữ liệu vào các trang quan trọng nhất. Việc kết hợp tối ưu kỹ thuật, cấu trúc website và chất lượng nội dung sẽ tạo nền tảng vững chắc cho quá trình index và xếp hạng bền vững. Đây là bước đi cần thiết đối với các website muốn mở rộng quy mô và duy trì hiệu suất SEO ổn định trong dài hạn.



