



In the world of SEO, there are a lot of tags that you need to be familiar with to optimize your website. One such tag is the robots meta tag. This tag tells search engines whether or not they should index a specific page of your website.
Let’s know more about the robots meta tag and what it does! We’ll also discuss some SEO practices in doing robots meta tags.
What are robots meta tags?
Robots meta tags instruct search engine crawlers what they should and shouldn’t do when they visit your web page. They’re a part of your site’s HTML code, and you can find them in the head section of your site’s source code.
What is meta robots tag use for?
The meta robots tag is an essential tag for SEO. It controls how search engine spiders index and follow the links on your website. Here is the list of the use of meta robots tags.
– To tell search engines not to index a page
– To tell search engines not to follow the links on a page
– To tell search engines how to handle different types of content on a page
– To give instructions to web crawlers and other web robots
– To help search engines understand the structure of a website
– To control the appearance of a website in search engine results pages (SERPs)
– To specify the relationship between different URLs on a website
– To manage duplicate content issues on a website
– To indicate when a page should be updated
– To guide search engine spiders through JavaScript or Flash websites
– To help search engines index only the most relevant pages on a website
– To prevent phishing attacks that use search engine results pages to deceive people into clicking malicious links
– To direct users to the correct page
Attributes & Directives
The attributes and directives of meta robots tags tell search engine crawlers what to do with a webpage’s content.
An attribute is a piece of information that tells the crawler how to handle the content on the page.
A directive is an instruction that tells a search engine crawler what to do with a webpage’s content.
Name Attribute
A name attribute is an HTML element that allows the webmaster to specify a name for the document. It is useful when the document is being used as part of a more extensive website and helps to keep track of which documents are which.
There are many user-agents/bots, each with its name. The more popular ones include Googlebot, Bingbot, and Yahoo! Slurp. Each bot has its purpose and function, so it’s essential to know which one you want to target when using meta robots tags. You can specify which bot you wish to target by including the name attribute.
Content Attribute
The content attribute is the value of the content field in a meta robots tag. The content field specifies the indexed contents of the file by the search engine.
Noindex

The noindex is a value you can assign to a robots meta tag’s content attribute. This value tells search engines not to index the page.
It is helpful if you have a page you do not want appearing in search results, like a thank you page after a form is submitted.
It is important to note that you can use the noindex directive in the robots meta tag and the X-Robots-Tag header.
When noindex is used in the robots meta tag, it applies to all search engines. When noindex is in the X-Robots-Tag header, it only applies to the specific search engine indicated in the header.
Index
The index tells search engine crawlers that they are allowed to index the page and include it in their search results.
You will use an index if you want a page to appear in search results.
Follow

The follow content attribute tells search engines whether they should follow the links on your page or not.
If the follow attribute is present, the search engine should follow the links on the page. It is the default behaviour for most search engines, so it is not necessary to specify this attribute unless you want to override the default behaviour.
Nofollow
Nofollow directive tells search engine crawlers not to follow any links on a page. It can be helpful if you have a page with many outbound links but don’t want to pass along your PageRank.
Noimageindex
Noimageindex tells search engines not to index images on a page. It tells robots not to index any page’s photos, follow any links, or show a page’s snippet when it appears on a SERP.
However, Google will still index the image and show it in the image result if someone adds the image somewhere else on the web.
None
None is equivalent to using noindex and nofollow tags simultaneously. You can use none if you want to prevent a search engine from indexing the page and following any links on the page.
You might do this on a development site that isn’t ready for public consumption or on pages with sensitive information. It’s also possible that your site has been penalized by a search engine, and using none is a way to remove your site from the search engine’s index until you’ve corrected the problems.
Noarchive
Noarchive tells search engines not to keep a cached copy of the page. It is helpful if you have pages that change frequently and don’t want search engines to stay outdated copies of your content.
Nocache
Nocache is like noarchive used only by MSN to prevent crawlers from caching the content of a page.
Nosnippet
Nosnippet directive instructs Google not to show a snippet for the page in search results. It can be helpful if you want to prevent your content from being indexed or appearing in search results.
The nosnippet directive is only respected by Google; other search engines may still show snippets for your page.
Noodyp/noydir
NoyDIR and NooDYP are obsolete or don’t have any use now as Yahoo! directory and DMOZ doesn’t exist anymore.
NoyDIR tells the search engine not to use the Yahoo! Directory page description in the search snippet.
NoODP prevents search engines from using the page description from DMOZ in the search snippet. ODP is the community that runs and maintains the DMOZ directory.
Unavailable_after
The Unavailable_after content attribute tells web robots when a page will no longer be available. It can be helpful if you have only temporarily unavailable pages, such as during maintenance periods.
Code Examples

There are meta robots tag examples that you can use in some usual scenarios:
Don’t index the page and do not follow the links to other pages:
<meta name=”robots” content=”none” />
Do not index but follow the links to other pages:
<meta name=”robots” content=”noindex, follow” />
Index the page but don’t follow the links to other pages:
<meta name=”robots” content=”nofollow” />
Do not keep a cached copy of the page:
<meta name=”robots” content=”noarchive” />
Do not index the image on the page:
<meta name=”robots” content=”noimageindex” />
Search Engines that Support Robots Meta Tag

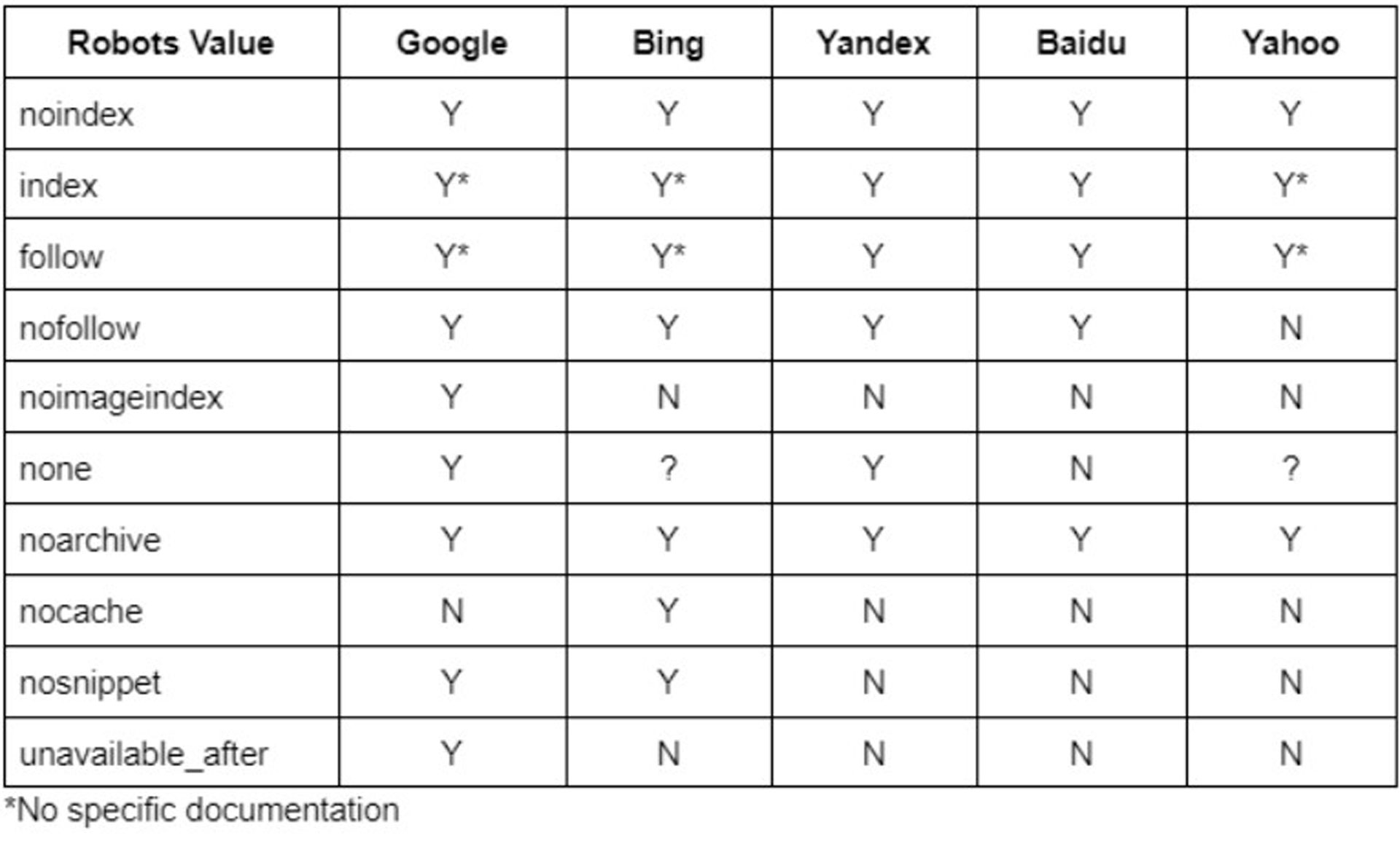
The following search engines support the meta robots tag: Google, Microsoft Bing, Yandex, Baidu, and Yahoo. If you want to index your website using these search engines, you must ensure that your pages have the correct robot meta tag in the HTML head section.
X-robots-tag
X-robots-tag is an HTTP header response that allows you to control specific elements of the page. You can use the X-robots-tag to control the visibility of certain elements on a page, such as a title or meta tags.
It is helpful if you want to prevent search engines from indexing certain parts of your website or if you want to hide certain elements from users who are not logged in.
To work correctly, the x robots tag may need access to your .htaccess or server files.
When to use the X‑robots-tag?
There following are the reasons why you should use x-robots-tag. It is for non-HTML file types such as PDFs and videos and gives directives sitewide rather than page-level.
– Controlling the indexation of content not written in HTML (like a flash or video)
– Blocking indexation of a particular element of a page (like an image or video) but not of the entire page itself
– Control index if you don’t have access to a page’s HTML specifically in the <head> section or if your site uses unchangeable a global header that cannot be changed
– Adding rules to whether or not a page should be indexed (ex., If a user has commented over 20 times, index their profile page)
SEO best practices
Be careful about how you use robot meta directives. Here are some best practices to follow:
First and foremost, don’t use the noindex directive unless you have a good reason. If your pages are being indexed anyway, then there’s no need to use this directive. It’s best to save it when you need it, such as when trying to prevent search engines from indexing duplicate content.
When it comes to the nofollow directive, you should use it sparingly as well. Overusing this directive can hurt your SEO efforts since it tells search engines not to follow any links on the page. It can make your pages less likely to rank well in search results.
Finally, remember that you can use the noarchive directive to prevent search engines from caching your pages. It can be helpful if you’re making changes to your website and don’t want those changes to be reflected in the search results immediately.
Conclusion
Meta robots tag helps control how search engines index and crawl your website. You can use different directives or commands to tell search engines what to do with a website.
Understanding each directive will help prevent common mistakes that could hurt a website’s SEO ranking. Each directive has a specific purpose and can be used to control different aspects of how search engines crawl and index a website. Knowing when and how to use each directive can help ensure that your website was being crawled and indexed correctly, which is essential for good SEO.

